Файл Robots.txt – управляем правильной индексацией сайта.
 Сегодня мы поговорим об очень полезном инструменте поисковой оптимизации сайтов под названием robots.txt. Узнаем что такое robots.txt и для чего нужен данный файл. Как с помощью него управлять индексацией сайта, запрещать или разрешать к индексации определенные страницы и разделы сайта. Как проверить правильность данного файла. Также научимся создавать правильный файл robots.txt для Joomla и для Wordpress.
Сегодня мы поговорим об очень полезном инструменте поисковой оптимизации сайтов под названием robots.txt. Узнаем что такое robots.txt и для чего нужен данный файл. Как с помощью него управлять индексацией сайта, запрещать или разрешать к индексации определенные страницы и разделы сайта. Как проверить правильность данного файла. Также научимся создавать правильный файл robots.txt для Joomla и для Wordpress.
Что такое Robots.txt и для чего он нужен.
Robots.txt – это обычный текстовый файл с расширением .txt, который лежит в корневой папке сайта. В нем прописаны различные директивы для поисковых роботов, сканирующих ваш сайт. Директивы говорят поисковым роботам, какие страницы сайта подлежат индексации, а какие страницы (или даже целые разделы) нужно запретить индексировать. При помощи него можно даже запретить к индексации сайт целиком. Часто это бывает полезно на начальных этапах разработки сайта, когда окончательная структура сайта еще не определена, например, постоянно создаются и удаляются разделы сайта, переносятся из одной категории в другую страницы сайта. Ведь если поисковый робот просканирует и проиндексирует ваш сайт, а после вы решите кардинально поменять навигацию сайта, то повторную индексацию изменений, возможно, придется ждать долго.
Управляем индексацией сайта.
Сканирование сайта поисковый робот начинает с просмотра файла Robots.txt. Установка данного файла на любой сайт предельно проста. Для этого просто нужно скопировать созданный файл robots.txt в корневую папку сайта. Если вы все правильно сделали, то он будет доступен по адресу http://адрес_сайта/robots.txt. В моем случае это http://buildsiteblog.ru/robots.txt.
Если данный файл отсутствует или к нему ограничен доступ, то поисковый робот считает, что можно индексировать все страницы сайта.
Существует пять основных директив (команд), используемых в данном файле, и которые вам нужно знать и уметь использовать. Мы их сейчас разберем.
Директива User-agent.
Правило написания:
User-agent: имя поискового робота, к которому применяется следующее правило.
Она говорит, для каких именно поисковых роботов будут предназначены другие директивы, которые будут прописаны после нее.
С данной директивы начинается любой файл robots.txt. Эту директиву ищет в первую очередь робот, просматривая файл. Если в файле отсутствует директива User-agent, то робот считает, что доступны к индексации все страницы сайта.
Рассмотрим примеры:
User-agent: * # Означает, что последующие директивы предназначены для всех поисковых роботов. User-agent: YandexBot # будет использоваться только основным индексирующим роботом YandexBot User-agent: googleboot # будет использоваться только основным индексирующим роботом googleboot
Если поисковый робот обнаружит в файле директиву User-agent, предназначенную для него, то данный робот будет игнорировать все директивы, описанные в разделе `User-agent: *`.
Поясню на примере:
User-agent: * Disallow: /cat1/ User-Agent: Googlebot Disallow: /cat2/
В этом примере для поискового робота Googlebot будут запрещены только URL, включающие `/cat2/`. Для всех остальных роботов будут запрещены только URL, включающие `/cat1/`.
В поисковой системе Yandex имеется несколько видов поисковых роботов. Каждый из них имеет свое название и предназначение:
- 'YandexBot' — основной поисковый робот, который индексирует наши тексты;
- 'YandexMedia' — этот поисковый робот индексирует мультимедийные данные;
- 'YandexImages' — данный робот занимается индексацией картинок на наших сайтах. Поэтому не удивляйтесь, почему страница сайта находится в индексе, а картинки данной страницы не проиндексировались. Просто на ваш сайт еще не пришел этот робот. Он более медленный;
- 'YandexCatalog' — данный робот проверяет сайты, которые находятся в Яндекс.Каталоге и временно снимает их с публикации в данном каталоге, если они не открываются. Если сайт снова становится доступным, то через некоторое время он вновь появится в каталоге;
- 'YaDirectFetcher' — этот робот сканирует страницы вашего сайта, на которых установлен код рекламных объявлений Яндекс.Директ для определения тематики показываемых на вашем сайте объявлений;
- 'YandexBlogs' — робот поиска по Яндекс блогам, индексирующий посты и комментарии;
- 'YandexNews' — робот Яндекс.Новостей;
- 'YandexPagechecker' — валидатор микроразметки;
- ‘YandexMetrika’ — робот Яндекс.Метрики;
- ‘YandexMarket’— робот Яндекс.Маркета;
- ‘YandexCalendar’ — робот Яндекс.Календаря.
В поисковой системе Google также имеются много поисковых роботов. Приведу несколько из них:
- Googleboot – основной индексирующий робот;
- Googlebot-Image – робот, сканирующий картинки;
- Mediapartners-Google – сканирует страницы для определения содержания AdSense;
- Adsbot-Google – сканирует страницы, оценивая качество целевых страниц для AdWords;
- Googlebot-Mobile – сканирует страницы для включения в индекс для мобильных устройств.
Директивы Allow и Disallow.
С помощью данных директив вы можете запретить или разрешить к индексации отдельные страницы или разделы сайта.
Примеры:
User-agent: * Disallow: / # блокирует доступ ко всему сайту для всех поисковых роботов
Следующий пример блокирует всем поисковым роботам доступ ко всему сайту, кроме страниц, начинающихся с `/seo-optimizatsiya-sajta/`:
User-agent: * Disallow: / Allow: /seo-optimizatsiya-sajta/
Т.е. в предыдущем примере будут запрещены к индексации все страницы моего сайта, кроме страниц категории "SEO оптимизация сайта", URL которых начинается на http://buildsiteblog.ru/seo-optimizatsiya-sajta
Почему в указанном выше примере директива Allow имеет больший приоритет? Ответ прост.
Если в файле присутствует несколько директив Allow и Disallow, то к конкретной странице будет применяться директива, у которой длина префикса URL будет больше.
В примере выше длина префикса `/seo-optimizatsiya-sajta/` у директивы Allow выше чем длина префикса `/` у директивы Disallow.
Рассмотрим еще один пример:
User-agent: * Disallow: / Allow: /seo-optimizatsiya-sajta/ Disallow: /seo-optimizatsiya-sajta/16-dmoz-katalog-sajtov-kak-dobavit-sajt-v-dmoz
В этом примере также запрещены к индексации все страницы сайта, кроме раздела "SEO оптимизация сайта". Однако в данной категории будет также запрещена к индексации страница "DMOZ - каталог сайтов. Как добавить сайт в ДМОЗ." Это опять же связано с тем, что к данной странице применяется директива с самым длинным URL префиксом `Disallow: /seo-optimizatsiya-sajta/16-dmoz-katalog-sajtov-kak-dobavit-sajt-v-dmoz`, следовательно у данной директивы наивысший приоритет.
Ну что же происходит, если к одной странице применяются директивы с одинаковой длиной URL префикса, как в примере ниже?
User-agent: * Allow: /raskrutka-sajta/8-sozdaem-favicon-dlya-sajta Disallow: /raskrutka-sajta/8-sozdaem-favicon-dlya-sajta
В данном примере страница сайта http://buildsiteblog.ru/raskrutka-sajta/8-sozdaem-favicon-dlya-sajta будет разрешена к индексации. Почему? Ответ прост:
При конфликте двух директив с одинаковой длиной префикса URL приоритет будет отдаваться директиве Allow.
Обязательно указывайте параметры в директивах `Allow:` и `Disallow:`, иначе эффект будет противоположный. Поясню на примере:
User-agent: * Allow: # запрещает к индексации весь сайт, действует также как Disallow: / Disallow: # разрешает к индексации весь сайт, действует также как Allow: /
Директива Sitemap.
Данная директива нужна для того, чтобы указать поисковому роботу на созданную вами карту сайта в формате xml. Подробно про карту для сайта и ее создание для Wordpress рассказано здесь. Создание карты для сайта на Joomla подробно описано здесь. Скормить поисковым системам карту сайта можно добавив ее непосредственно в инструментах вебмастера поисковых систем, но т.к. не все поисковые системы предоставляют такую возможность, то лучше дополнительно известить роботов о ее существовании при помощи файла robots.txt.
Пример добавления моей карты сайта:
User-agent: * Disallow: # разрешает к индексации весь сайт, т.к. указан без параметра Sitemap: http://buildsiteblog.ru/index.php?option=com_xmap&view=xml&tmpl=component&id=1 # добавление карты сайта
Директива Host.
Известно, что к сайту можно обратиться как с префиксом `WWW`, так и без него, например, http://buildsiteblog.ru и http://www.buildsiteblog.ru. В поиске также может быть доступна страница вашего сайта с префиксом `WWW` и без него. Это плохо с точки зрения поисковой оптимизации (SEO), когда одна и та же страница присутствует в поиске по разным адресам (с `www` и без `www`), т.е. появляются дубли страниц. Известно, что поисковые системы очень не любят дубли страниц и могут даже понизить ваш сайт в поисковой выдаче. Чтобы избавиться от дублей нужно сообщить поисковым роботам, какая из зеркал вашего сайта (с `www` или без `www`) является главной и указать это в файле robots.txt, чтобы индексировалось только это зеркало.
Но для начала нам нужно определиться с тем, какое из зеркал у нас будет главным. Я для моего блога выбрал главным зеркало с адресом без `www`. Выбор я этот сделал руководствуясь следующим. Известно, что доменное имя второго уровня котируется выше, чем доменное имя третьего уровня. Адрес buildsiteblog.ru является доменным именем второго уровня. Адрес www.buildsiteblog.ru является доменным именем третьего уровня. Следовательно в качестве главного зеркала я выбрал адрес buildsiteblog.ru. Если у вас другое мнение на этот счет, буду рад, если поделитесь им в комментариях.
Директиву Host понимает только поисковый робот Яндекса, поэтому, для ее указания обычно создают отдельный раздел User-agent: Yandex.
Пример указания главного зеркала в файле robots.txt:
User-agent: * Allow: / Sitemap: http://buildsiteblog.ru/index.php?option=com_xmap&view=xml&tmpl=component&id=1 Host: buildsiteblog.ru # указывает главное зеркало
Данная директива может быть только одна во всем файле robots.txt.
Использование дополнительных спецсимволов *, $ и #.
Спецсимвол '*' означает любую (в том числе пустую) последовательность символов. Смысл данных символов лучше понять на примерах:
User-agent: * # здесь символ * означает, что следующие правила применяются для всех поисковых роботов Allow: / # разрешает к индексации весь сайт Disallow: /*?start= # запрещает страницы, в URL которых присутствует ?start= Disallow: /*?limitstart= # запрещает страницы, в URL которых присутствует ?limitstart=
По умолчанию к концу каждого правила, описанного в robots.txt, приписывается '*':
User-agent: * Disallow: /category1 # запрещает страницы, в URL которых присутствует /category1 Disallow: /category1* # тоже самое
Чтобы отменить '*' на конце правила, можно использовать спецсимвол '$', например:
User-agent: * # здесь символ * означает, что следующие правила применяются для всех поисковых роботов Allow: / # разрешает к индексации весь сайт Disallow: /category1$ # запрещает /category1, но не запрещает /category1.html
Спецсимвол `#` как вы уже заметили используется для комментирования. Все, что находится после этого символа и до первого перевода строки не учитывается.
Проверяем правильность файла robots.txt.
Если вы составили свой файл robots.txt и хотите проверить будет или не будет индексироваться интересующая вас страница вашего сайта, то это можно сделать несколькими способами.
Во первых можно зайти на webmaster.yandex.ru и на открывшейся странице справа под кнопкой "Начать работу" кликнуть по ссылке "Проверить Robots.txt".
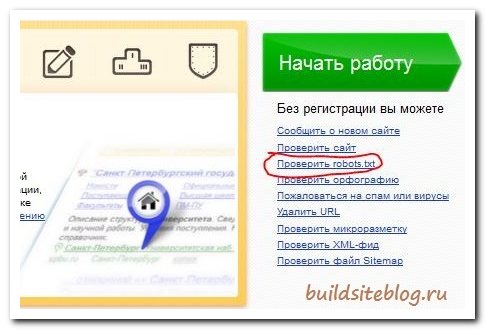
Если вы уже загрузили ваш файл на хостинг, то в поле "Имя хоста" указываете адрес вашего сайта и нажимаете кнопку "Загрузить Robots.txt с сайта".
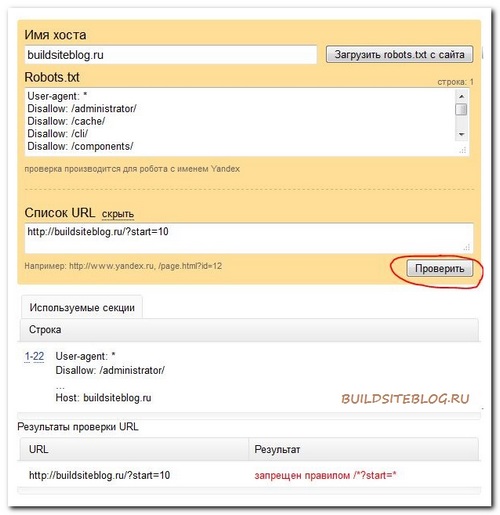
В поле "robots.txt" появится содержимое вашего файла. Если же вы еще не успели загрузить файл на хостинг, то просто скопируете руками содержимое вашего файла в это поле.
Теперь, чтобы узнать действие файла на интересующий вас URL вашего сайта, нажимаем на ссылку "Список URL Добавить", вписываем нужный URL (для примера, я на скриншоте указал http://buildsiteblog.ru/?start=10) и нажимаем на кнопку "Проверить".
Появится результат проверки. В моем случае URL, который я вбил, запрещен правилом `/*?start=*`.
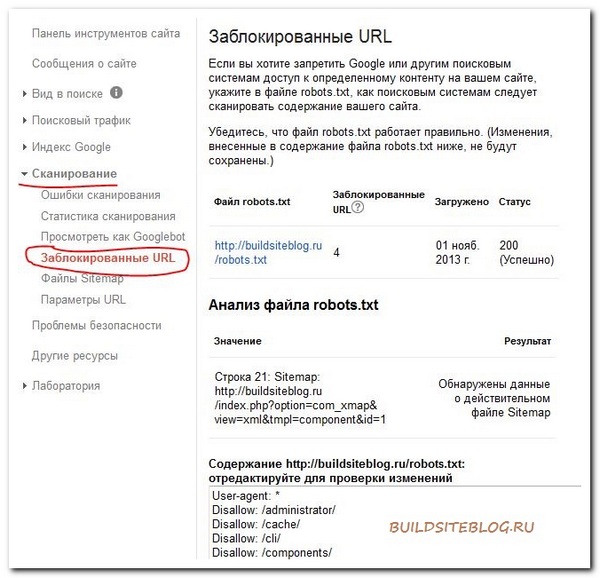
Сделать такую же проверку можно и в инструментах для веб-мастеров Google. Для этого в разделе "Сканирование" выбираем пункт "Заблокированные URL".
Есть и более простой способ проверить, закрыта ли интересующая нас страница от индексации файлом robots.txt.
Для этого заходим по адресу адурилки (AddURL) яндекса webmaster.yandex.ru/addurl.xml, вставляем адрес страницы, вводим капчу и нажимаем кнопку "Добавить". Если страница закрыта от индексации файлом, то сверху появится соответствующая надпись.
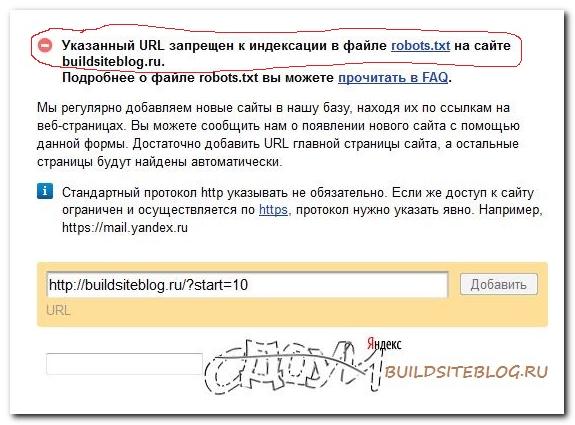
Кстати этот метод хорош еще и тем, что с помощью него можно быстро проверять на закрытость файлом от индексации не только адреса своего сайта, но и адреса любого другого сайта.
Примеры файлов robots.txt для Joomla и Wordpress.
Напоследок приведу примеры базовых файлов для Joomla и Wordpress, а вы при желании, можете их дополнить или изменить.
Пример файла Robots.txt для сайта на Wordpress:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Host: buildsiteblog.ru Sitemap: http://buildsiteblog.ru/sitemap.xml.gz Sitemap: http://buildsiteblog.ru/sitemap.xml
Пример файла Robots.txt для сайта на Joomla:
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: buildsiteblog.ru Sitemap: http://buildsiteblog.ru/index.php?option=com_xmap&view=xml&tmpl=component&id=1
На этом у меня все. Надеюсь, статья была для вас полезной.
Вы можете помочь проекту, рассказав о нем в социальных сетях:
Спасибо!
